

Getty Images
In the world of AI, what might be called “small language models” have been growing in popularity recently because they can be run on a local device instead of requiring data center-grade computers in the cloud. On Wednesday, Apple introduced a set of tiny source-available AI language models called OpenELM that are small enough to run directly on a smartphone. They’re mostly proof-of-concept research models for now, but they could form the basis of future on-device AI offerings from Apple.
Apple’s new AI models, collectively named OpenELM for “Open-source Efficient Language Models,” are currently available on the Hugging Face under an Apple Sample Code License. Since there are some restrictions in the license, it may not fit the commonly accepted definition of “open source,” but the source code for OpenELM is available.
On Tuesday, we covered Microsoft’s Phi-3 models, which aim to achieve something similar: a useful level of language understanding and processing performance in small AI models that can run locally. Phi-3-mini features 3.8 billion parameters, but some of Apple’s OpenELM models are much smaller, ranging from 270 million to 3 billion parameters in eight distinct models.
In comparison, the largest model yet released in Meta’s Llama 3 family includes 70 billion parameters (with a 400 billion version on the way), and OpenAI’s GPT-3 from 2020 shipped with 175 billion parameters. Parameter count serves as a rough measure of AI model capability and complexity, but recent research has focused on making smaller AI language models as capable as larger ones were a few years ago.
The eight OpenELM models come in two flavors: four as “pretrained” (basically a raw, next-token version of the model) and four as instruction-tuned (fine-tuned for instruction following, which is more ideal for developing AI assistants and chatbots):
OpenELM features a 2048-token maximum context window. The models were trained on the publicly available datasets RefinedWeb, a version of PILE with duplications removed, a subset of RedPajama, and a subset of Dolma v1.6, which Apple says totals around 1.8 trillion tokens of data. Tokens are fragmented representations of data used by AI language models for processing.
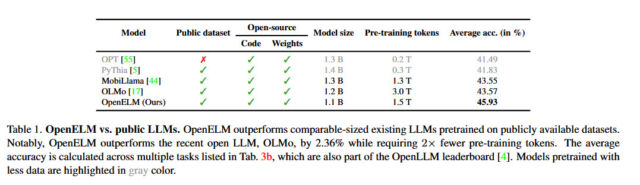
Apple says its approach with OpenELM includes a “layer-wise scaling strategy” that reportedly allocates parameters more efficiently across each layer, saving not only computational resources but also improving the model’s performance while being trained on fewer tokens. According to Apple’s released white paper, this strategy has enabled OpenELM to achieve a 2.36 percent improvement in accuracy over Allen AI’s OLMo 1B (another small language model) while requiring half as many pre-training tokens.
Apple
Apple also released the code for CoreNet, a library it used to train OpenELM—and it also included reproducible training recipes that allow the weights (neural network files) to be replicated, which is unusual for a major tech company so far. As Apple says in its OpenELM paper abstract, transparency is a key goal for the company: “The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks.”
By releasing the source code, model weights, and training materials, Apple says it aims to “empower and enrich the open research community.” However, it also cautions that since the models were trained on publicly sourced datasets, “there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts.”
While Apple has not yet integrated this new wave of AI language model capabilities into its consumer devices, the upcoming iOS 18 update (expected to be revealed in June at WWDC) is rumored to include new AI features that utilize on-device processing to ensure user privacy—though the company may potentially hire Google or OpenAI to handle more complex, off-device AI processing to give Siri a long-overdue boost.